
Các mô hình ML mới xuất hiện hàng giờ nhưng tốc độ nhanh này cũng có những hạn chế; sự phát triển dựa trên giả thuyết có thể giúp giảm thiểu những điều đó.
Chúng ta đang sống trong thời đại AI! Mỗi ngày, nhiều công cụ AI và mô hình ML mới đang được tạo ra, đào tạo, phát hành và thường được quảng cáo. Khi nhìn vào
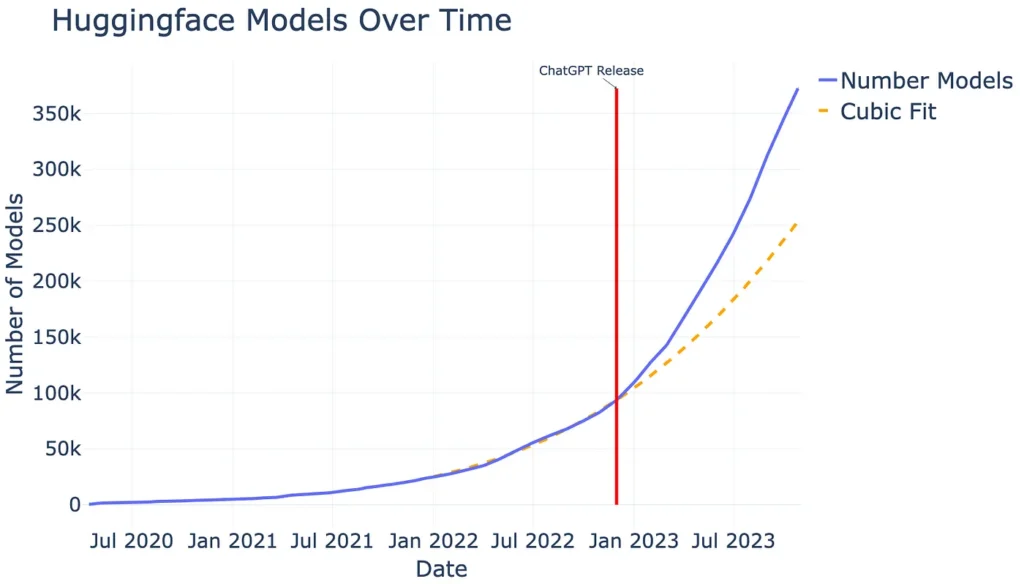
Ví dụ: Ở trang Hugging face, chúng tôi thấy gần 400.000 mẫu có sẵn hiện nay (2023–11–06) so với ~84.000 mẫu có sẵn vào tháng 11 năm 2022 (xem Hình 1). Chỉ trong một năm, số lượng mẫu mã đã tăng mạnh khoảng 470%. Hãy nhớ rằng, Huggingface không phải là nền tảng mô hình ML duy nhất hiện có. Thêm vào đó, nhiều mô hình thậm chí không có nguồn mở. Vì vậy, thật an toàn khi nói rằng số lượng mô hình ML có sẵn thực tế cao hơn nhiều.
Có thực sự cần phải có sự lạm phát quá mức của các mô hình như vậy không?
Sự phấn khích về AI là rất lớn và điều đó trước hết là tốt. AI có tiềm năng tìm ra giải pháp – hoặc ít nhất là giảm thiểu – một số thách thức toàn cầu nghiêm trọng nhất như biến đổi khí hậu hoặc đại dịch. Ngoài ra, AI có thể làm cho các công việc hàng ngày trở nên hiệu quả hơn và do đó cải thiện sự cân bằng giữa công việc và cuộc sống của chúng ta. Do đó, nghiên cứu phát triển AI và đưa các mô hình ML đến với cộng đồng là bước đi đúng đắn và cần thiết! Tuy nhiên, với tốc độ phát triển và sự phấn khích nhất định trong cộng đồng AI, tôi tự hỏi: liệu có thực sự cần đến sự lạm phát quá mức của các mô hình như vậy không? Cuối cùng thì ai sẽ được hưởng lợi từ việc này?
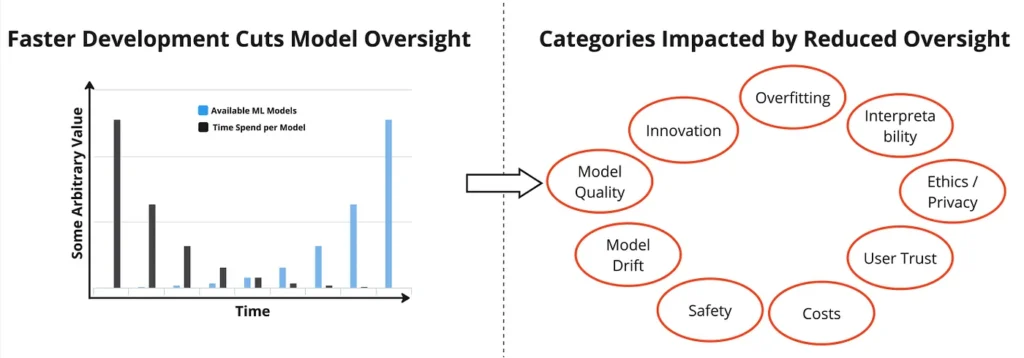
Rủi ro tiềm ẩn của lạm phát mô hình
Một trong những nhược điểm chung của sự “hưng phấn” và “cường điệu” đối với một chủ đề nhất định là khi động cơ và công việc bắt nguồn không hướng cụ thể đến một mục tiêu mà mang tính hời hợt và rộng rãi hơn. Những lợi ích tiềm tàng nói trên của AI không đến từ việc có nhiều mô hình hời hợt mà đến từ các mô hình chuyên biệt giải quyết các vấn đề khó khăn.
Ngoài ra, tốc độ phát triển, triển khai và quảng cáo mô hình hiện nay còn đi kèm với một số nhược điểm mà có lẽ tất cả chúng ta đều đã gặp phải. Điều quan trọng là phải giải quyết những vấn đề này để đảm bảo kết quả tốt nhất trong tương lai. Một số nhược điểm tiềm ẩn của tốc độ hiện tại trong phát triển AI:
- Chất lượng: với tốc độ tiếp cận thị trường, việc theo dõi cộng đồng và đánh giá đúng kết quả mô hình cũng như tài liệu nghiên cứu đã trở nên quá khó khăn. Nhược điểm sẽ là số lượng lớn các mẫu mã và dịch vụ có sẵn với chất lượng thấp do chưa được kiểm tra và xem xét nghiêm ngặt. Ngoài ra, các số liệu hỗ trợ chất lượng như khoảng tin cậy hầu hết đều bị giảm do tốc độ tiếp cận thị trường.
- Tác động + An toàn: một số lượng lớn các mô hình đang được phát triển ngày nay không lấy con người (hoặc thiên nhiên) làm trung tâm và không có mục tiêu hoặc trường hợp sử dụng thực sự hữu ích. Tuy nhiên, mọi hoạt động phát triển sản phẩm phải luôn tập trung vào việc biến thế giới thành một nơi tốt đẹp hơn. Các nhà phát triển phải tập trung vào những gì có thể có tác động tích cực chứ không phải phát triển “chỉ một chatbot khác”. Ngoài ra, các nhà phát triển còn phải loại trừ những tác hại tiềm ẩn đến từ mô hình của mình và đảm bảo an toàn (tương tự như đề xuất này).
- Quyền riêng tư + Bản quyền: Các mô hình hiếm khi được ghi lại và khó có thể theo dõi cách giải quyết quyền riêng tư và bản quyền. Điều này có thể gây ra những hậu quả tiêu cực cho cá nhân. Khi làm việc với dữ liệu nhạy cảm, việc lập mô hình rất nguy hiểm vì ngay cả cơ sở dữ liệu vectơ sau khi nhúng cũng không thân thiện với quyền riêng tư và có thể dễ dàng được thiết kế ngược (như đã trình bày bởi Morris và cộng sự 2023). Ngoài ra, các quy định mới như Đạo luật AI của EU sẽ có tác động đến các mô hình đó, thực thi việc tuân thủ quyền riêng tư.
- Lỗ đầu tư: Ngay cả với tốc độ đưa ra thị trường nhanh chóng, bất kỳ dự án AI nào cũng cần có nguồn lực (kỹ sư có tay nghề cao, chi phí tính toán đáng kể, bảo trì sản phẩm). Lợi tức đầu tư cho một doanh nghiệp sẽ không được đưa ra nếu sản phẩm AI thu được có chất lượng thấp hoặc không phục vụ mục đích rõ ràng của người dùng. Thông thường, cần có giai đoạn khám phá sản phẩm trước khi phát triển sản phẩm để dự đoán lợi tức đầu tư tiềm năng. Thực tiễn này thường bị vi phạm đối với AI với tốc độ đưa ra thị trường như hiện nay.
Tóm lại, tốc độ phát triển AI nhanh không chỉ là điều tốt mà còn tiềm ẩn những bất lợi và bất lợi cho doanh nghiệp và cá nhân.
Giảm lạm phát mô hình AI bằng cách phát triển dựa trên giả thuyết
Như đã đề cập trước đó, sự phấn khích hiện nay xung quanh AI trước hết là một điều tốt. Mục đích của câu chuyện này là không để ngừng phát triển AI hoặc làm chậm nó lại. Hoàn toàn ngược lại. Mục đích là hướng sự phấn khích tích cực vào các mục tiêu cụ thể và tạo ra chất lượng hơn là số lượng. Ý tưởng là khuyến khích mọi Kỹ sư AI và Nhà khoa học dữ liệu dành thêm một chút thời gian khi bắt đầu mỗi dự án và đặt một số câu hỏi cơ bản, như: “Ai sẽ được hưởng lợi từ việc này?” và “Chúng ta muốn đạt được điều gì?”.
những gì câu chuyện này đề xuất không mang tính cách mạng chút nào, nó chỉ đơn giản là tuân theo các phương pháp khoa học.
Thay vì cách tiếp cận mang tính khám phá, nơi người ta bắt đầu chỉ phát triển LLM tiếp theo mà không có tầm nhìn rõ ràng và do đó, làm tăng giá trị cộng đồng, bạn nghĩ thế nào về việc bắt đầu từ cuối và thảo luận về trường hợp sử dụng sản phẩm? Ví dụ, điều đó có thể là đưa ra mục tiêu cho dự án trước tiên: “Các LLM cơ bản hiện tại rất phức tạp và khó có thể chạy tại chỗ. Đó là điều chúng tôi muốn giải quyết”. Với điều này, dự án trở nên có ý nghĩa. Nhưng ý nghĩa không phải là tất cả, một giả thuyết rõ ràng sẽ khiến tác phẩm càng tinh gọn hơn. Ví dụ:
“Có thể đào tạo một LLM nhẹ có thể chạy tại chỗ và vẫn hoạt động >70 trên bộ tiêu chuẩn LLMU”.
Có một mục tiêu rõ ràng và giả thuyết xuất phát sẽ giúp hợp lý hóa toàn bộ công việc phát triển. Nó cũng sẽ giúp đo lường sự thành công và đóng góp có ý nghĩa cho cộng đồng. Kết hợp với việc xem xét tài liệu/mô hình, nó sẽ ngay lập tức phác thảo xem dự án đề xuất đã đạt được ở nơi nào khác hay chưa và do đó, chỉ tạo ra công việc dư thừa. Nói cách khác, những gì câu chuyện này đề xuất không mang tính cách mạng chút nào, nó chỉ đơn giản là đi theo các phương pháp khoa học.
Tia sáng của sự đổi mới
Sở dĩ đề xuất các phương pháp khoa học là vì những vấn đề hiện nay xuất phát từ tốc độ phát triển nhanh chóng của AI đã được cộng đồng khoa học biết đến. Các nhà khoa học phải học hỏi từ vô số tài liệu nghiên cứu để có thể đóng góp có ý nghĩa cho cộng đồng nghiên cứu. Cùng với tốc độ của các phòng thí nghiệm nghiên cứu lớn, rất dễ nảy sinh cảm giác “không có đủ thời gian để đọc hết”. Điều này và áp lực xuất bản đã dẫn đến cuộc khủng hoảng về khả năng tái sản xuất. Phương pháp khoa học ở đây để khắc phục những vấn đề đó.
Các phương pháp khoa học đã được phát triển và cải tiến qua nhiều thế kỷ và đang là cốt lõi của bất kỳ dự án khoa học nào. Cho rằng tốc độ phát triển AI nhanh chóng rất giống với lượng tài liệu khoa học khổng lồ, việc điều chỉnh những nguyên tắc đó là điều hợp lý.
Rất nhiều đột phá khoa học không bắt đầu từ phòng thí nghiệm, chúng bắt đầu từ một ý nghĩ được hình thành thành một giả thuyết
Là một tác dụng phụ tích cực, các phương pháp khoa học không chỉ được phát triển để tiêu chuẩn hóa công việc và kết quả thử nghiệm mà còn được thực hiện để tăng cường đổi mới. Dành thời gian để xem xét các tài liệu hiện có và hình thành các giả thuyết là cốt lõi của sự đổi mới. Rất nhiều đột phá khoa học không bắt đầu từ phòng thí nghiệm, chúng bắt đầu từ một ý nghĩ được hình thành thành một giả thuyết.
Ví dụ, cộng đồng khoa học đưa ra lựa chọn đăng ký trước. Điều đó có nghĩa là, các nhà khoa học công bố mục tiêu, giả thuyết và phương pháp của họ trước khi thực sự tiến hành các thí nghiệm và phân tích. Khái niệm này cũng có thể được áp dụng để phát triển AI.
Như đã nói, tôi thực sự khuyến khích mọi người vạch ra mục tiêu bằng các giả thuyết trước khi bắt đầu bất kỳ dự án AI hoặc ML nào! Ngoài ra, tôi hy vọng rằng
ôm mặt và các nền tảng nổi bật khác một ngày nào đó sẽ yêu cầu các Kỹ sư và Nhà khoa học phải đăng ký trước các mục tiêu và giả thuyết của họ trước khi họ có thể bắt đầu làm việc trên một mô hình. Tôi chắc chắn nếu một nền tảng lớn như Ôm Mặt bắt đầu thì những nền tảng khác cũng sẽ theo sau.
Túm lại là
Tốc độ phát triển AI hiện nay vừa thú vị vừa đầy thách thức. Thú vị về những lợi ích mà các mô hình mới mang lại nhưng đầy thách thức do có quá nhiều mô hình có sẵn và chưa biết về chất lượng cơ bản, quyền riêng tư, an toàn và lợi tức đầu tư của chúng.
Các phương pháp khoa học, như phát triển dựa trên giả thuyết, có thể giúp khắc phục những vấn đề đó và thậm chí có thể thúc đẩy sự đổi mới bằng cách đảm bảo Kỹ sư AI/ML và Nhà khoa học dữ liệu tập trung phát triển theo hướng mục tiêu và giả thuyết được xác định trước.
Đây là thời đại của AI nên điều quan trọng nhất là đảm bảo chúng ta tạo ra tương lai tốt nhất từ nó cho tất cả chúng ta.
Tất cả các hình ảnh, trừ khi có ghi chú khác, là của tác giả.
Bài viết này ban đầu được xuất bản trên Hướng tới khoa học dữ liệu.
- Trí tuệ nhân tạo, Định nghĩa AI, AI sáng tạo

Benjamin Thurer, Benjamin Thürer là Nhà khoa học dữ liệu và hiện đang giữ chức vụ Giám đốc Khoa học dữ liệu tại Unacast. Ở vị trí của mình, anh và nhóm của mình chịu trách nhiệm xây dựng các sản phẩm tập dữ liệu có thể mở rộng, cung cấp thông tin chi tiết về khả năng di chuyển của con người. Trước đó, anh ấy đã lấy bằng Tiến sĩ nghiên cứu về khả năng học tập vận động trong não người và thực hiện một nghiên cứu sau tiến sĩ về Khoa học thần kinh để nghiên cứu các mối tương quan thần kinh của ý thức.
Để lại một bình luận